
Product Release Planning: Rocks, Gravel & Sand
Enterprise products tend to deliver in defined releases rather than a stream of continuously delivered improvements. The main benefit of this is to help customers with change management and forward planning: a bunch of new and enhanced features will arrive at this time and here’s what you need to know to prepare your users for them. At Singletrack we deliver three major releases per year and have a roadmap covering the four releases beyond the one currently in development.
Smaller utilities and consumer products can be delivered in a continuously updated manner but, inevitably, the internal view will aggregate these enhancements into something like a release, even if it is just by time.
So, at some point, every product owner will be asked questions like:
-
What did we deliver in the last release(/quarter/half year/whatever)?
-
What will we deliver in the next release?
-
What about the two or three releases after that?
-
Can we fit this customer request in the current or next release? If not, when is the earliest possible date
-
We want to deliver this new area of capability. When can we fit it in? How long will it take?
The Internet is awash with discussions about how and when to estimate, what the usefulness and value of estimates are, and whether we should even produce estimates at all. But whether you’re a fan of Story Points (ugh) or No Estimates (also, ugh) you’re still going to need to answer questions like the above and neither of these two extremes of estimation dogma are going to be very helpful in doing so.
Big Things
Where we have settled in our release planning process is to focus almost exclusively on the ‘Big Things’. A Big Thing is a major new area of functionality or a major uplift to an existing one.
From a marketing or roadmap communication point of view a Big Thing is something that merits a bullet point in a presentation about the release.
From a technical planning perspective a Big Thing is something that will occupy a significant fraction of the development team for the duration of the release development cycle.
A Big Thing should make as much sense to the board who are going to approve the budget for it, and the sales people who are going to sell it, as the product owner and product development team who are going to deliver it.
We don’t get too hung up on whether one Big Thing is exactly the same size as another Big Thing. Sometimes a major new area of development may require the delivery of several Big Things (e.g. a new data integration platform we built consisted of a migration of the underlying technology, a new data integration framework and a new user interface = 3 Big Things delivered over three releases) and sometimes we might do a lot of individual pieces of work under the umbrella of one Big Thing (e.g. we delivered a number of related but individual customer requests and feedback items as part of improving an existing capability).
The key thing is that when we plan a new release we only plan the Big Things. We know from experience how many Big Things the team can deliver per release and so that is the number of Big Things we plan for the new release. If the team is growing or shrinking we know from experience what it takes to add another Big Thing per release or the point at which we need to remove a Big Thing from the release plan.
At present our Big Thing capacity for our main development team is 3. In a recent release we delivered:
-
A new area of capability that gave allowed a particular type of user to get a lot more value from the system
-
A significant uplift in an existing area of capability to make it easier to use and more relevant to non-expert users
-
The user interface element of the new data integration platform mentioned above
Of course, this is all rather vague but that is somewhat the point. We don’t spend days trying to define new areas of work in terms of detailed stories and their story points but neither do we just shrug and say “you’ll get what you get”. We spend a little bit of time splitting up or grouping together the priority things we need to deliver into things we can all — from developer to CEO — agree are Big Things. Once we’ve agreed that these are the Big Things we are going to deliver in the release, we then manage the hell out of doing just that. In 7 years of using this system we’ve always managed to deliver the Big Things we promised in a release.
Rocks, Gravel and Sand
Why does this work? When I first explained this approach to the Singletrack board I used the analogy of a jar that we want to fill. You have some rocks, some gravel and some sand.
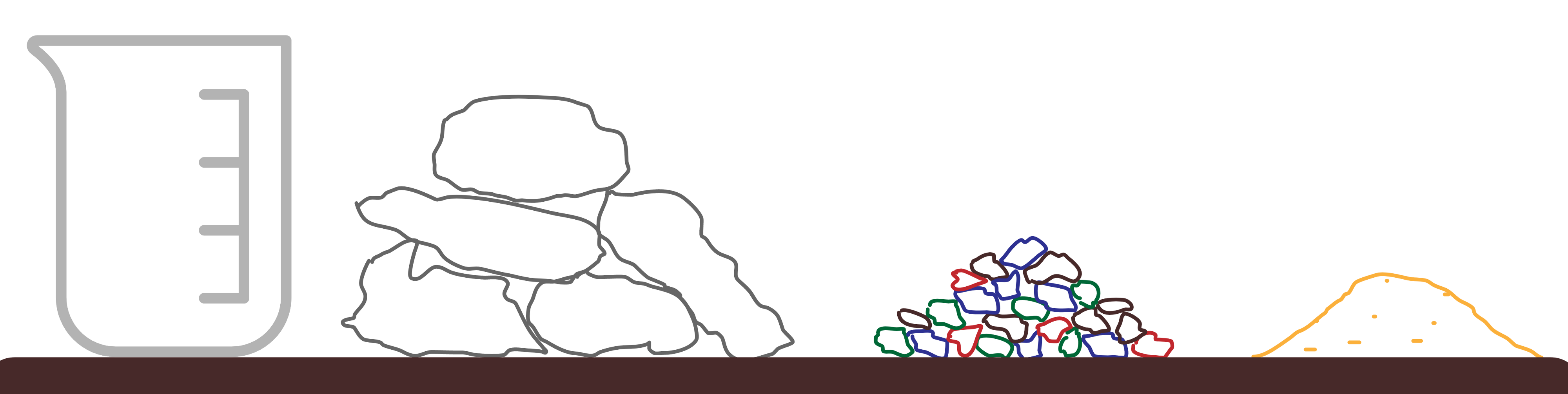
The jar is the capacity of the team for the release. We always assume the capacity of the team is fixed for a release, even if we’re hiring. People don’t arrive and make a material difference from day one, the existing team will need to dedicate time to helping them get up to speed, and planning on the ‘expected productivity’ of an unknown quantity is an exercise in futility.
There are only so many rocks you can fit in a jar and, to stretch the analogy, if you try and cram one more rock in than actually fits, you risk breaking the jar.
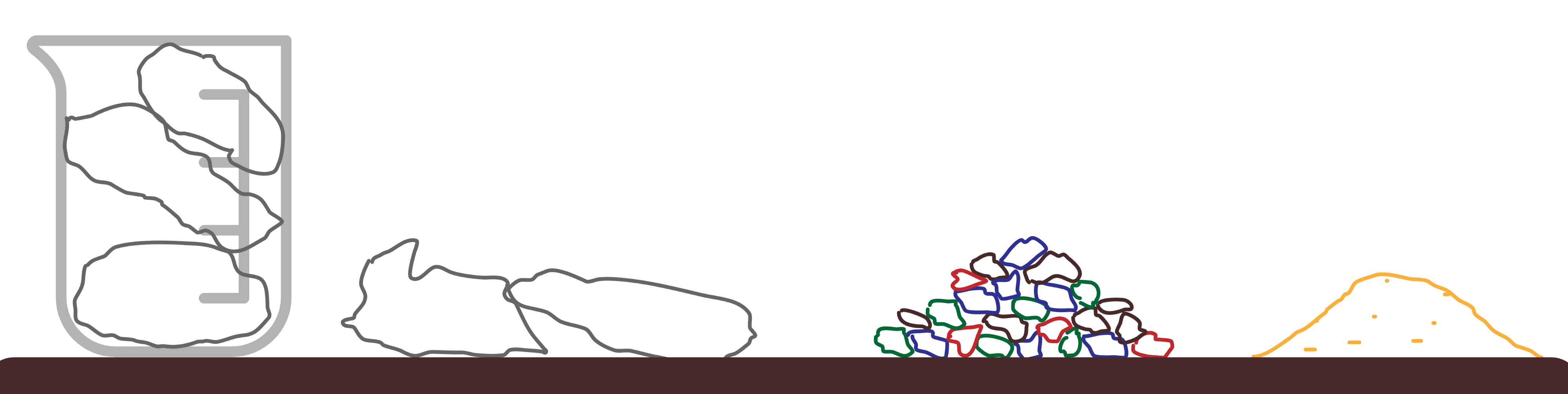
But a jar with three rocks in it isn’t full; there’s a load of space around the rocks. In product development terms the team will be working flat out on the Big Things most of the time but there will also be times when they’re waiting for feedback or clarification, where there are an odd number of developers and so one developer can’t pair, when a piece of work is completed 90 minutes before the end of the day and it doesn’t make sense to start on the next Big Thing story on the board, and so on.
Don’t plan on this time! It is variable and unpredictable. But it is great for delivering other pieces of work:
- ‘Gravel’: smaller features or enhancements such as the smoothing off of a clunky UX or a variant on an existing function. Interrupting work such as implementing some critical feedback to patch back to the live release or helping with an urgent support request. Something that can be done solo in 3–4 days and part-paired or paired in 1–3 days.
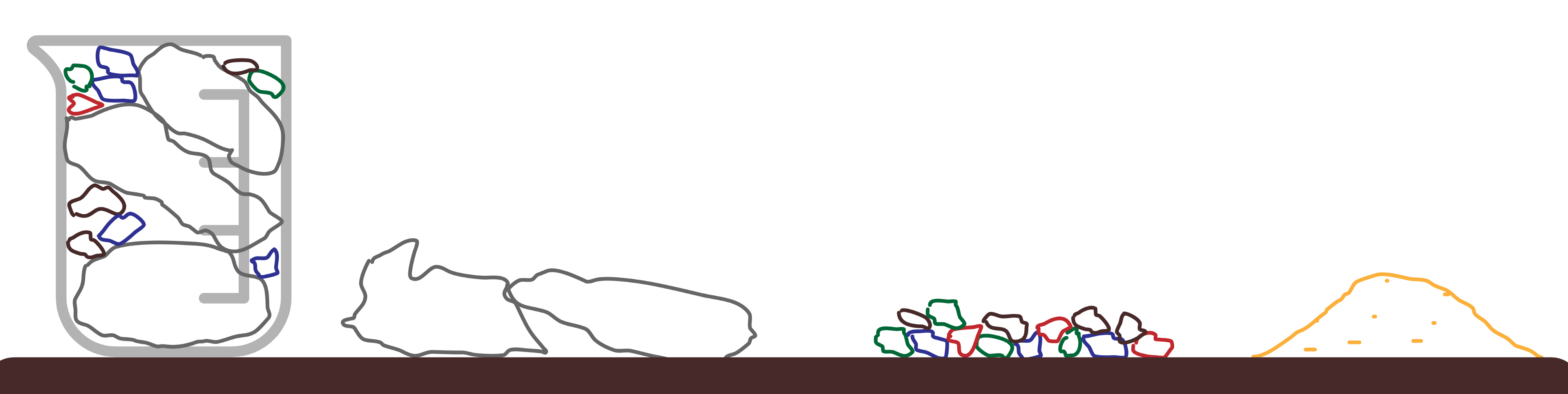
- ‘Sand’: micro enhancements such as improving the placement of a button, fixing a minor bug or clarifying a confirmation message. Interrupting work such as helping support with a data migration script or helping with the configuration of a new feature in a production environment. Something that can be done solo in < half a day.
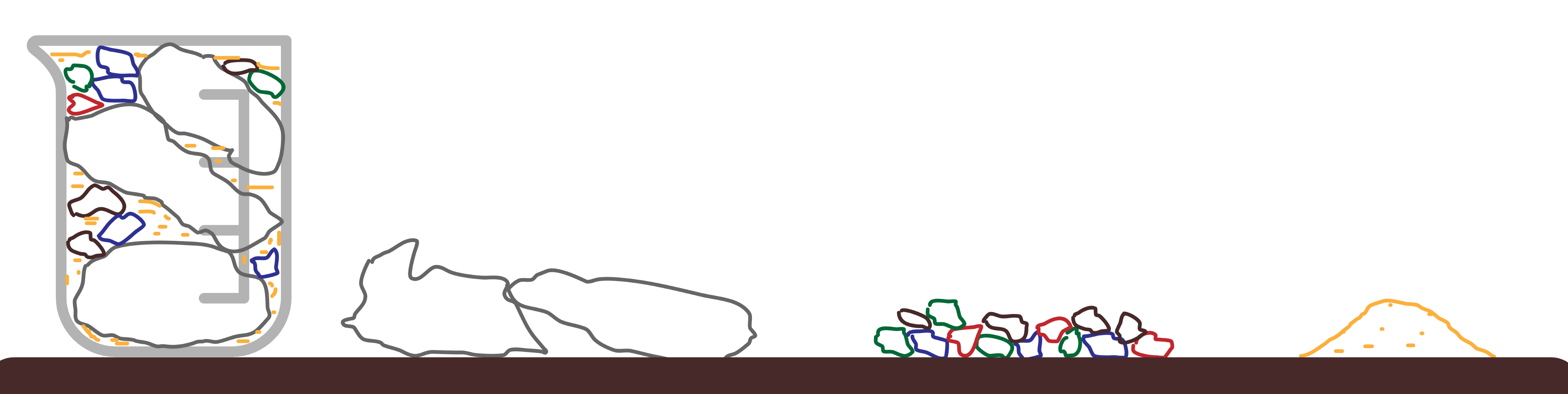
In addition to the ‘main release backlog’ for the Big Things we maintain two priority lists.
The first is for small features. These are often direct requests from customers that we have identified as ‘quick wins’ where we can make customers happy by rapidly responding to their requests. Or they’re enhancements that are never going to be prioritised as part of a Big Thing but nevertheless smooth off some rough edges or add to the overall quality of the product.
The second is a defect list of low priority improvements we could make, whether they are non-critical bugs or just things that could be made clearer or more efficient.
This work is just done as time allows. Developers decide what time they have available and just work on the highest priority item of the relevant size.
There are a few things going on here that are important:
-
We’re planning for some slack in a release: the ‘empty space’ in the jar. There are plenty of product management approaches1 that recommended scheduling no more than 80% or 85% of a release’s capacity to deal with ‘the unexpected’. We don’t worry about whether it is exactly 85%, a bit more or a bit less. We don’t worry about whether this is consistent from release to release. Instead, we focus on the priority features that we know, based on experience, we have the capacity to deliver.
-
We are focussing on the priorities that matter most. On any given day in release development the most important thing to work on is one of the Big Things. If developers can’t do that for some reason there is a list of other work to pick up until they can go back to working on a Big Thing or the release comes to an end.
-
We can deal with the fact that the Big Things can grow or shrink as the release is developed. Because we’re not promising to deliver the ‘gravel and sand’ work it doesn’t matter too much if the scope of the Big Things changes. Whether we manage 5% gravel and sand work or 30% is irrelevant if we deliver the Big Things. Of course if all three of the Big Things start to significantly grow then some priority calls need to be made. But that’s normal product development management; the point is that there is some capacity built into the system to deal with the expected flux around a major piece of development work.
-
We don’t spend a lot of time estimating or re-planning if we don’t need to. We don’t need to break everything out into user stories with estimates in order to capacity plan. We don’t need to constantly update estimates and burn-down charts as we work. If things start to look tight on one or more Big Things, and there is something critical about their delivery (e.g. a customer needs exactly this capability to migrate off an existing system ours is replacing), then we might go to this level of detail at the point it becomes necessary. But, generally speaking, as long as we’re progressing well and the Big Things are coming together nicely, we can focus on doing the work rather than planning the work.
-
We can broadly plan future releases beyond the current one. Of course, the further out in time you go, the more uncertain things become. But if you organise your roadmap in terms of Big Things then you can see what you’ll deliver over the next year or so at the rate of X Big Things per release or you can determine what your ambition for the year is and see at what rate you need to grow your team to be able to deliver that.
This is a model, and every model breaks down at a certain level of detail or when viewed from a particular angle. If you need to rapidly scale up your delivery team to deliver a major new product by the end of the year, the model might tell you that you need to grow the team 300% in the next 9 months to deliver 3x the number of Big Things as in the current release. But there’s a lot more to 3x growth than just hiring three times as many developers as you currently have, so the model starts to creak.
But it will give you a rough idea of the scale of the problem and focus conversations on the really hard part: how to onboard that many developers quickly, and what additional roles might be needed to support them, rather than on the relatively easy part of what functionality do we want to deliver.
More importantly, when things aren’t that turbulent it is a decent way of predicting with confidence and with an appropriate level of precision what you can deliver in the next release and the ones soon after that, given what you know today. And that’s really all anyone can really ask of a release plan.
-
3M have for years scheduled product developers at 85% of their time according to Harvard Business Review. Rich Mironov quotes the same figure. ↩